通配符
Windows/Dos下的通配符 *和?
\b 单词的开头或结尾,单词的分界处
. 匹配除了换行符以外的任意字符。
* 指定数量,前边的内容可以连续重复出现任意次以使整个表达式得到匹配
.* 任意数量的不包含换行的字符
\bhi\b.*\bLucy\b 匹配单词hi,任意个字符,不能使换行,最后匹配Lucy
\d 匹配一位数字
- 只匹配它本身或者减号
0\d{2}-\d{8} {2} 必须连续重复匹配两次 {8} 必须连续重复匹配8次
\s 匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。
\w 匹配字符或数字或下划线或汉字等
对于中文/汉字的特殊处理是由于 .Net提供的正则表达式引擎的支持,其它情况下需要查看相关文档
\ba\w*\b 匹配以字母a开头的单词,是以任意数量的字母或数字,在单词结束处
\d+ 匹配1个或更多连续的数字。 + 和 * 类似,区别:*(可能是0次) +(可能1次或更多)
\b\w{6}\b 匹配刚好6个字母/数字的单词常用的元字符

后向引用
规则从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,依次类推。向后引用用于重复搜索前面某个分组匹配的文本。
Eg:\1 代表分组 1 匹配的文本。
\b(\w+)\b\s+\1\b \b(\w)\b 匹配单词 \s+ 匹配任意空白符 \1这里等价于 \b(\w+)
自定义子表达式 (?<word>\w+) 或者 (?’word’\w+) 将该组名指定为word常用的分组 ()语法
捕获:
(exp) 匹配exp,并捕获文本到自动命名的组里
(?<name>exp) 匹配exp,并捕获文本到名称为 name的组里(也可写成 (?’name’exp) )
(?:exp) 匹配exp,不捕获匹配的文本,也不给此分组分配组号
零宽断言:
(?=exp) 匹配exp前面的位置
(?<=exp) 匹配exp后面的位置
(?!exp) 匹配后面跟的不是exp的位置
(?<!exp) 匹配前面不是exp的位置
注释:
(?#comment) 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读零宽断言
用于查找某些东西(但并不包括这些内容)之前或之后的东西。它们像 \b ^ $ 那样用于指定一个位置。断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配
\b\w+(?=ing\b) 匹配以ing结尾的单词的前面部分(除了ing以外的部分)
(?<=\bre)\w+\b 匹配以re开头的单词的后半部分(除了re以外的部分)零度负预测先行断言
查找不是某个字符或某个字符类里的字符的方法(反义)
(?!exp) 断言此位置的后面不能匹配表达式 exp
\d{3}(?!\d),匹配三位数字,而且这三位数字的后面不能是数字
\b((?!abc)\w)+\b 匹配不包含连续字符串 abc的单词
\b\w*q[^u]\w*\b 包含后面不是字母u的字母q的单词出现的问题,如果q出现词尾,会自动将词后的符号给[^u],负向零断言就可以解决此问题。特点:只匹配不消耗字符。
修改后:
\b\w*q(?!u)\w*\b零度正回顾后发断言
(?<!exp) 断言此位置的前面不能匹配表达式exp
(?<![a-z])\d{7} 匹配前面不是小写字母的七位数字
(?<=<(\w+)>).*(?<=<\/\1>)
(?<=<(\w+)>) 等价于 (?<=exp) exp= <(\w+)>
.* 匹配任意字符
(?<=<\/\1>) 等价于 (?<=exp) exp= <\/\1> 其中 \/ 是转义 \1是后向引用(别名)
匹配出来的结果类似于 <b>字符</b>注释
(?#comment) 包含注释。 要包含注释,最好启用“忽略模式里的空白符”,这样在编写表达式时能任意的添加空格。
启用“忽略模式里的空白符”,在#后面到这一行结束的所有文本都将被当成注释忽略掉
(?<=<(\w+)>).*(?<=<\/\1>) 可以改写为
(?<= # 断言要匹配的文本前缀
<(\w+)> # 查找 <字母或数字> (即HTML/XML标签)
) # 前缀结束
.* # 匹配任意文本
(?= # 匹配任意文本
<\/\1> # 查找 <> 起来的内容
) # 后缀结束贪婪匹配
在使整个表达式能得到匹配的前提下匹配尽可能多的字符。
a.*b 它将会匹配最长的以 a开始,以b结束的字符串 懒惰匹配
在使整个表达式能得到匹配的前提下匹配尽可能少的字符。
a.*?b 会匹配尽可能短的 以a开始,以b结束的字符串 正则表达式的规则:最先开始的匹配拥有最高的优先权
正则表达式常用的处理选项
C#中,可以使用Regex(String,RegexOptions) 构造函数来设置
.Net中可以常用的正则表达式选项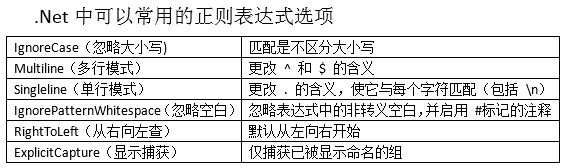
说明:单行模式和多行模式之间没有任何关系,更改的是通配符的含义
平衡组/递归匹配
由 .Net支持,其他语言/库不一定
(?’group’) 把捕获的内容命名为 group 并压入堆栈(类似入栈)
(?’-group’) 从堆栈上弹出最后压入堆栈的名为 group 的捕获内容,如果堆栈本来为空,则本分组匹配失败(类似出栈)
(?(group)yes|no) 如果堆栈上存在以名为 group 的捕获内容,继续匹配 Yes部分的表达式,否则继续匹配 No部分的表达式
(?!) 零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败事例
< # 最外层的左括号
[^<>]* # 匹配括号的内容
(
(
(?’open’<) # 把捕获到的open压入栈
[^<>]* # 匹配不是括号的内容
)+
(
(?’-open’) # 把捕获到的open出栈
[^<>]* # 匹配不是括号的内容
)+
)*
(?(open)(?!)) # 判断栈中是否存在open,有则匹配失败
> # 最外层的右括号平衡组最常见的就是匹配HTML,匹配<div>的例子 <div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>
<div[^>]*> # 头标签
[^<>]* # 匹配不是 <>的内容
(
(
(?'Open'<div[^>]*>) # 将 <div[^>]*>名成别名 open压入栈中
[^<>]* # 匹配不是 <>的内容
)+ # 该元组重复1或更多次
(
(?'-Open'</div>) # 将 <div[^>]*>名成别名 open出栈
[^<>]* 匹配不是 <>的内容
)+ # 该元组重复1或更多次
)* # 整个元组重复0或一次
(?(Open)(?!)) 判断栈中是否还存在Open别名的元组,有则不匹配
</div> # 闭合标签



